VCDX Skill Compute
Originally posted in September 2015 on vmice.net
Compute skills include skills regarding the CPU and Memory part of the technology stack. So the server part. It not that simple anymore.
Servers themselves are pretty simple things, just a motherboard of some kind with a CPU (or eight) connected to some memory. Its how these things are connected to the rest of the stacks that are getting ever more complicated.
- Simple Rack Servers.
- Not so long ago you only had rack mounted servers with local disk and perhaps IO connectors to network and storage (could use the same component to move the IO though)
- Blade Form Factor
- Then the blade form factor was introduced which in many cases had internal infrastructure components such as network/fiber channel switches shared between the blades in each chassis. Recently the blade form factor has seen a new spike in usability with the promise of network/storage path convergence, that is using the bandwidth from the same line for network and storage.
- Converged Solutions
- These are like the aforementioned convergence blade form factor (Cisco UCS as a large player), and the other half of the convergence market, the compute/storage convergence like VMware vSAN.
- Hyper-Converged Solutions
- Yes there is a Hyper version of convergence. That is a solution that includes compute (CPU, memory), Storage and Management with huge emphasis on scalability and ease of use. Large players include Nutanix and Simplivity.
What does this have to do with compute skills? Well everything. Because the solution that is selected after gathering the business requirements and doing the logical design plays a large role in the solution itself. But in reality most projects have a specific vendor constraints based on either politics, staff preference or cost.
That choice will impact almost every design quality there is.
- Availability can be impacted with chassis design for blades, boot device options, memory HA features, number of IO cards per server etc.
- Manageability can be impacted with server management tools (blade management), ease of servicability, Image deployment, Scalability etc.
- Performance can be impacted by CPU models available, memory available, IO cards available, internal caching capacity, effect on memory channel placement etc.
- Recoverability can be impacted by server image backups, config backups or even support contracts with vendors.
- Security can be impacted by CPU features, access control to hardware, security features available (encryption) etc.
Just going through that small comparison will give a very general idea about what you need to know about compute side of the stack. It no longer just compute in the sense of CPU and memory, it’s a whole section of things that need to be considered.
There are things that are directly connected to the compute layer in any vSphere environment:
- vNUMA and its relations to NUMA
- pCPU and vCPU ratios and rationality around that kind of over provisioning
- CPU Vendor
- CPU and Memory considerations (Channels, slots and QPI’s) and how it relates to VM placement
As soon as you have some sort of list of thing you want to catch up on, the learning process will begin. I created a Quizlet for each skill I wanted to increase my skill level on and went over the deck everyday. When learning a lot of new information over a short period of time (60 days) this is the process the yield the best result in my case.
In some cases I even created a deepdive slide for the slide deck if I thought I wouldn’t be able to explain it fast enough without a diagram.
Here is an example deep dive diagram for CPU and Memory considerations:
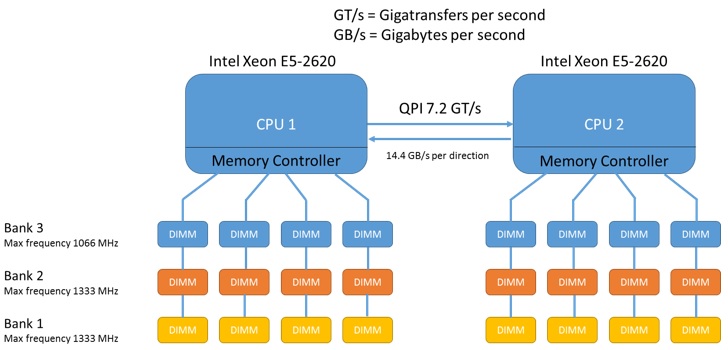
Rene Van Den Bedem has a great blog post on the matter and I highly recommend reading this and everything in his VCDX blog post collection. http://vcdx133.com/2014/04/24/vcdx-study-plan-compute-vsphere/